AI 交易系统如何自我进化:不是让 AI 自动炒币,而是把它关进闭环
很多人对“AI 交易系统”的想象,是让模型直接看行情、直接点买卖按钮,然后系统会自己越来越赚钱。
这个想象很性感,但工程上非常危险:它会把 幻觉、过拟合、边界混乱 三个高概率事故源,直接连到资金曲线上。
我们在 ProBitForge 的做法更朴素,也更残酷:不追求“AI 自动炒币”,只追求一件事:
把 AI 的能力压进一套可审计、可复盘、可验证、可阻断的闭环里。
这篇文章是 research only,not financial advice;backtests are not live performance;not an instruction to trade。
如果你希望持续跟进这类“系统搭建 + 风控工程”的内容,可以从 System Build 标签开始:<https://www.probitforge.com/tag/system-build/>
1) 自我进化不是“自动乱改”,而是“闭环 + 门禁”
所谓“自我进化”,不是 AI 自己改策略然后自动上线。那不是进化,是自毁。
真正能长期活下来的系统,必须回答三个硬问题:
1. 事实从哪里来? 没事实就没有学习,只有幻觉。
2. 候选改造怎么被裁决? 没裁决就会退化成自动过拟合机器。
3. 出了事谁负责、怎么回放? 没回放就没有复盘,下一次只会重复同一种错。
闭环的要点是:每一次“变得更聪明”,都必须被事实证明;每一次“想上线”,都必须被门禁阻断或放行。
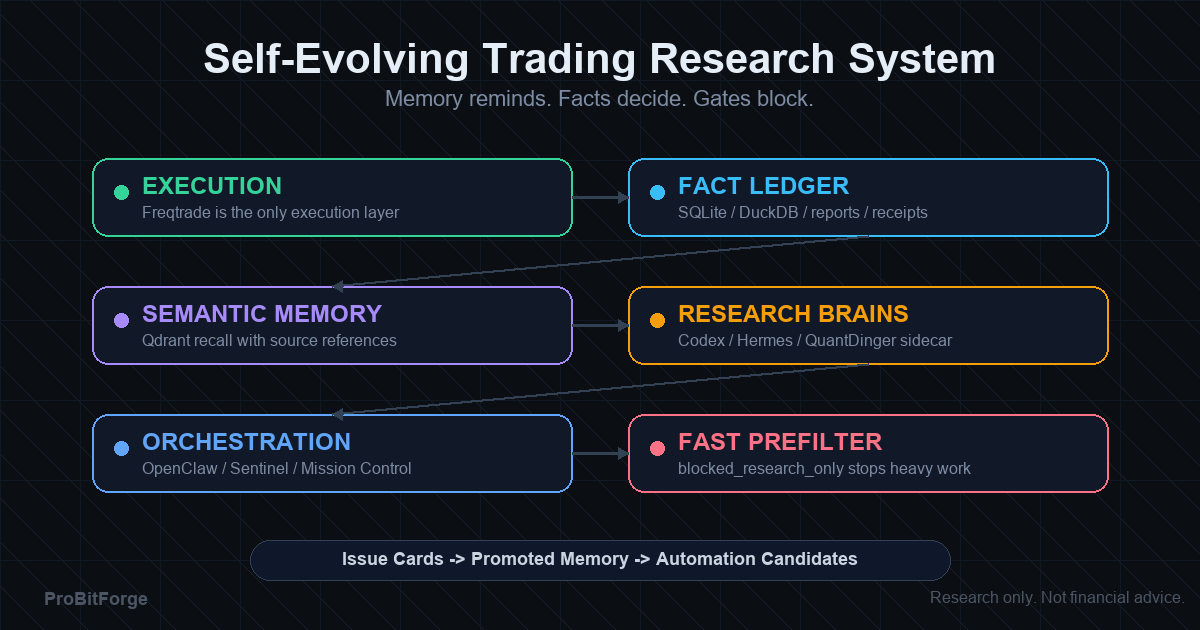
2) 六层架构:谁负责想,谁负责记,谁负责执行
我们把系统拆成六层,各司其职,谁也别越界:
| 层级 | 组件 | 主要职责 | 能否直接影响实盘 | | --- | --- | --- | --- | | 执行层 | Freqtrade | 回测、dry-run、实盘执行 | 是(唯一执行层) | | 事实层 | SQLite / DuckDB | 保存交易、回测、信号、审计事实 | 间接(裁判层) | | 指挥层 | OpenClaw | 哨兵监控、复盘、门禁编排、候选管理 | 可以阻断/建议,不直接下单 | | 记忆层 | Qdrant | 语义记忆、相似案例召回、RAG 证据层 | 否 | | 研究层 | Hermes | 解释失败、提出假设、设计验证计划 | 否 | | 工程层 | Codex | 把候选落成代码/脚本/测试/文档 | 否(必须过门禁) |
一句话:Freqtrade 执行;SQLite/DuckDB 记事实;Qdrant 记经验;Hermes 想方案;Codex 落工程;OpenClaw 管门禁。
这套分工的好处只有一个:把“想法”和“资金”隔开,让系统失控的概率下降一个量级。
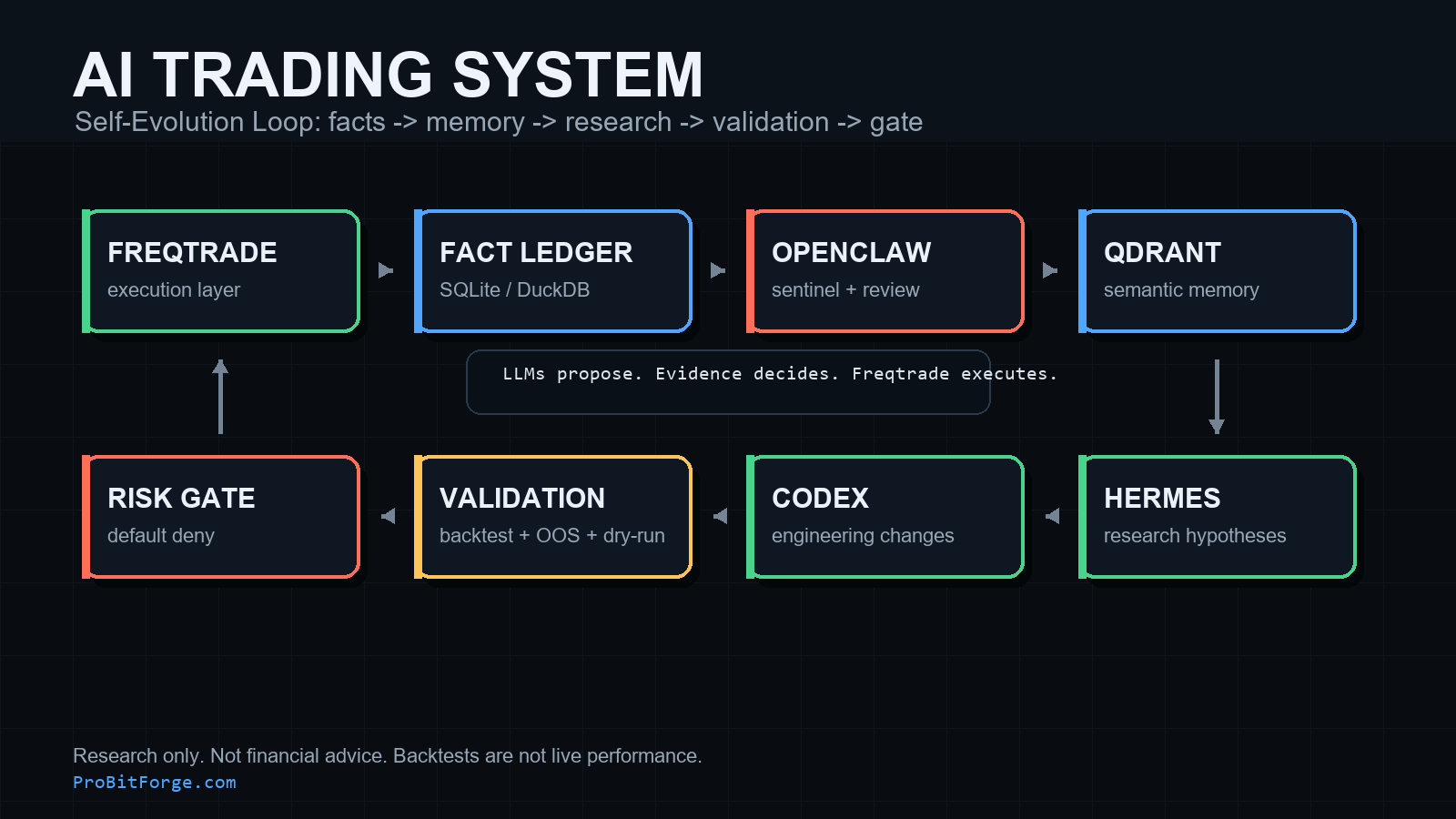
3) 自我进化闭环(端到端)
你可以把闭环理解成一个“研究工厂流水线”:
1. Freqtrade 产生交易与回测事实。 2. SQLite/DuckDB 把事实固化成可审计账本。 3. OpenClaw 把事实变成结构化复盘样本(交易案例、风险事件、候选改造)。 4. Qdrant 只存“高信噪比样本”,用于相似经验召回。 5. Hermes 基于事实 + 召回证据提出候选假设(策略、风控、数据、工作流)。 6. Codex 把候选工程化:代码、配置、测试、验证脚本、文档回执。 7. 验证链路跑起来:回测、样本外、walk-forward、成本敏感性、dry-run。 8. 风控门禁裁决:不通过就阻断,通过才允许晋级。 9. 新结果写回事实摘要与记忆库,成为下一轮进化材料。
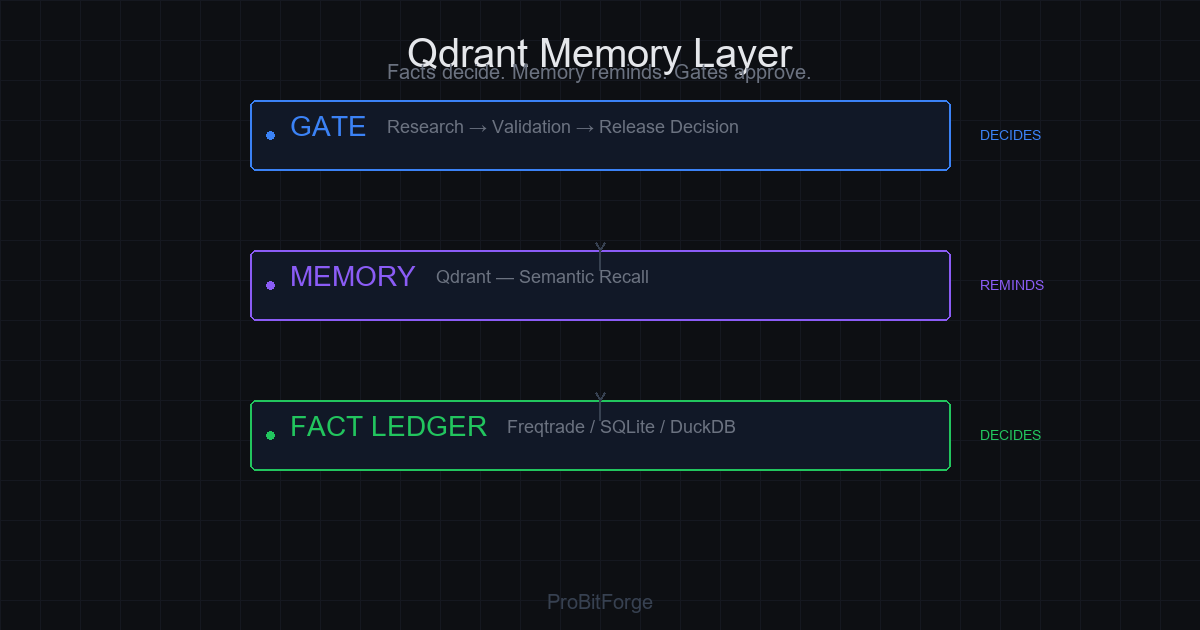
这里有个关键点:记忆帮助推理,但事实负责裁决。
3.1) 进化评分卡:候选有没有资格“晋级”
为了避免“回测看起来很美”这种典型自欺,我们给每个候选改造打一个非常务实的评分卡:
| 指标 | 你要回答的问题 | 最低要求 | | --- | --- | --- | | Evidence | 证据在哪?能回链到事实吗? | 必须有 source id | | Robustness | 跨市场状态还成立吗? | 不能只在单一牛市有效 | | Overfit Risk | 有没有过拟合嫌疑? | 必须做样本外检查 | | Drawdown | 最大回撤可接受吗? | 不得突破风控阈值 | | Trade Count | 交易次数够吗? | 过少则置信下降 | | Cost Sensitivity | 手续费/滑点后还有效吗? | 必须检查 | | Explainability | 能解释收益来源吗? | 不能只看收益曲线 | | Reversibility | 能干净回滚吗? | 必须保留旧版本 |
这张表的意义是:让候选晋级变成“工程审批”,而不是“感觉不错就上”。
4) Qdrant 的真实角色:语义记忆,不是交易大脑
很多人误把向量库当“智能引擎”。但在交易系统里,Qdrant 最合适的位置是:
- 召回“类似行情下我们曾经怎么死过”
- 召回“类似哨兵告警后来是否演化成亏损”
- 召回“某类参数改动是否造成过拟合”
- 召回“某个 Prompt/Agent 协作方式成功过还是坑过”
它不应该做:
- 裁定真实 PnL(那是事实库和交易所的工作)
- 替代回测/样本外验证(那是验证链路的工作)
- 直接批准实盘(那是门禁的工作)
- 把“相似案例”当统计显著性(那是过拟合的开端)
把它放在“语义记忆层”,反而能把系统拉回正确轨道:先召回证据,再提出假设,再用事实打脸或证实。
4.1) 记忆入库原则:宁愿少,也要干净
语义召回是一把双刃剑。你往记忆里塞什么,未来它就会拿什么来“影响”你的假设。
我们更偏向这套入库原则:
1. 只收高信噪比样本:一次失败的复盘、一次明确的风险事件、一份结构化实验结论。 2. 必须可回链:每条记忆都能回到事实账本/原始报告,而不是孤儿笔记。 3. 显式打标签:市场状态、风险等级、策略版本、时间窗口,不然召回就是瞎碰瓷。 4. 允许“删掉垃圾”:低质量样本进库,会污染未来所有召回。
5) 迭代逻辑:为什么我们会主动判定“这族候选不够资格”
真正难的不是“把策略调得更好看”,而是敢于说:证据不够,就停。
一个典型失败模式是“阈值族微调”:你不断调阈值,曲线确实好看一点,但稳定性没有变硬,只是把噪声当信号。
所以我们对候选晋级的态度更接近“发布工程”而不是“写周报”:
1. 证据不到阈值,不晋级 不是“差不多能用”,而是“可复现、可解释、可样本外站住”。
2. 样本外与 walk-forward 不过,直接阻断 否则系统会自动退化为过拟合机器。
3. 允许“停止”,不允许“自欺” 停止某条路线,反而是在节省未来的风险预算。
这也是为什么我们会明确地把某些候选族留在研究层,拒绝进入 dry-run,更不可能进入 live。
6) 一个可落地的检查清单(给想复刻闭环的人)
如果你想把自己的 AI 交易系统从“能想”推进到“能活”,你至少需要:
1. 一份可审计事实账本(能回链到每一次决策) 2. 一套结构化复盘产出(把失败变成可学习样本) 3. 一层语义记忆(只收高信噪比样本,支持相似召回) 4. 一个研究脑(提出假设,不触达执行按钮) 5. 一个工程落地者(把假设变成可测试变更) 6. 一条验证流水线(回测/样本外/walk-forward/dry-run) 7. 一道风控门禁(默认阻断,证据充分才放行) 8. 一个“写回”机制(把新结果变成下一轮的事实与记忆)
做到这八条,你的系统不一定赚钱,但它会具备最关键的能力:不重复犯同一种错。
6.1) P0 最小闭环(建议先做这个)
不要一上来就追求全自动。先把“半自动研究闭环”跑起来更关键:
1. 拉取最近一段交易/回测事实(以事实账本为准)。 2. 产出结构化复盘(失败原因、风险标签、市场状态)。 3. 把高质量复盘写入语义记忆库,支持相似召回。 4. 研究脑基于“事实 + 召回证据”提出候选假设。 5. 工程落地者把假设变成可验证的变更与脚本。 6. 验证链路跑完,门禁裁决是否晋级。
P0 目标不是赚钱,是让系统开始“认真地不犯重复错误”。
7) 最后再强调一次:AI 不碰买卖按钮
AI 可以读文档、做复盘、写代码、写报告、提假设。
但它不应该在没有验证、没有门禁、没有审计的情况下,直接触达资金。
这篇文章是 research only,not financial advice;backtests are not live performance;not an instruction to trade。