Building a Memory Layer for Trading Research with Qdrant
交易系统最大的风险不是"策略不够聪明",而是"系统不记得自己怎么死过"。
回测报告会过期,日志会被滚动覆盖,失败候选的复盘最终沉入文件夹深处。当你六个月后遇到一笔相似的亏损,你大概率会重做一遍已经做过的研究、犯一遍已经犯过的错。
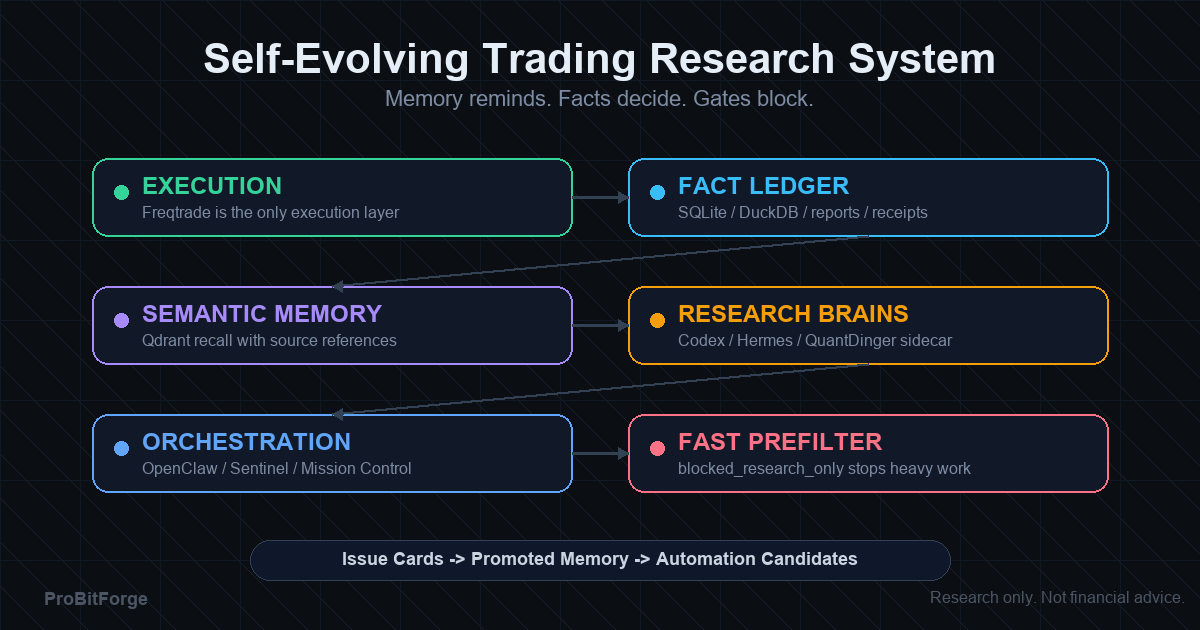
这就是为什么 ProBitForge 在事实账本和执行层之外,建立了一层语义记忆。
这篇文章是 research only,not financial advice;backtests are not live performance;not an instruction to trade。语义召回不构成交易证明——它只是提醒。
如果你刚来 ProBitForge,可以先看我们的系统定位:<https://www.probitforge.com/what-probitforge-is-building/>
1) 为什么交易系统需要记忆
一个交易研究系统每天会产生大量事实:
- Freqtrade 记录每一笔回测和 dry-run 成交。
- SQLite/DuckDB 保存聚合后的交易事实、候选评审、门禁结果。
- 哨兵记录每一次告警、每一次风控阻断。
- 策略评审会记录每一次"为什么这个候选不能晋级"。
事实是有的。问题是:当你在研究一个新候选时,你能多快找到"历史上和这个情况最像的案例"?
不是"最赚钱的案例",而是"最像的失败案例"。
这不是让 AI "记住怎么赢"。这是让研究流程记住"怎么亏的、为什么停了、缺了什么证据"。
所以记忆层的目标非常明确:
> 减少重复犯错,不是绕过验证流程。
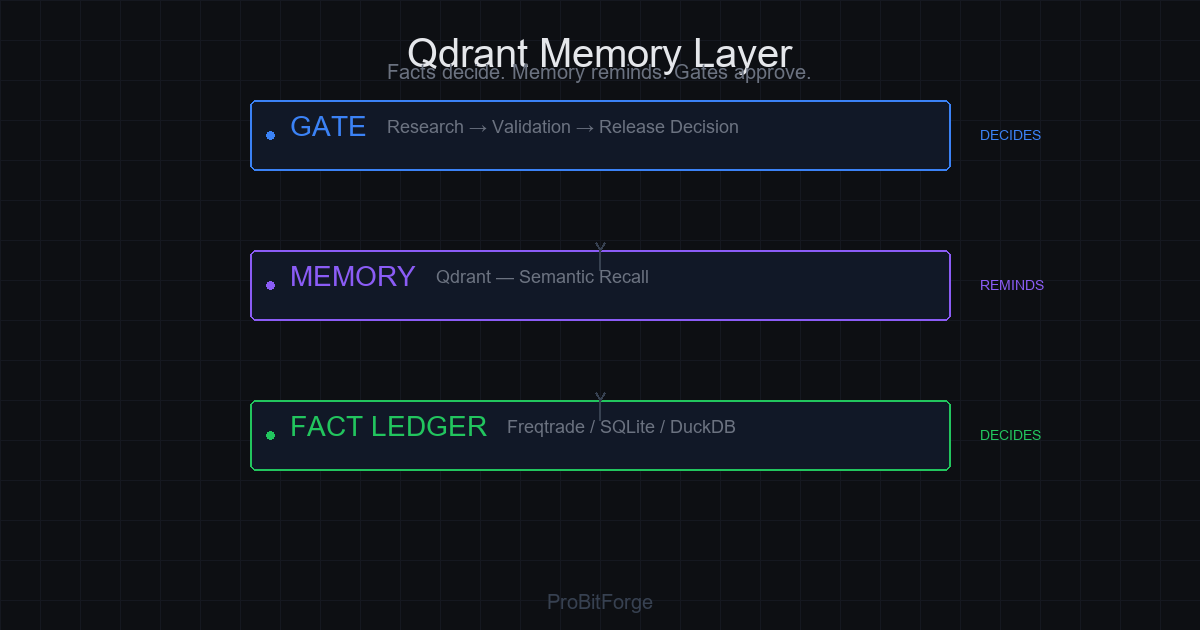
2) 事实账本 vs 语义记忆
这是我们整个系统最关键的一条分界线。
| 问题 | 谁来回答 | | --- | --- | | 某笔订单的真实成交价是多少? | Freqtrade / SQLite 事实层 | | 这次回测的精确收益和回撤? | Freqtrade 回测产物 | | 这个候选能不能进入 dry-run? | 门禁 + 事实账本 | | 历史上有没有和这个情况相似的案例? | Qdrant 语义记忆 | | 这个风险告警和过去的哪次事故像? | Qdrant 语义记忆 |
事实账本回答"是什么",语义记忆回答"像什么"。
如果你用语义记忆回答事实问题,你会得到合理的幻觉。如果你用事实账本回答相似性问题,你会得到一堆精确但不相关的数字。
在我们的系统里,这两条线严格分离:Qdrant 的 payload 里保存事实 ID,但不保存唯一事实本身。每条记忆都必须能回链到原始报告或数据库 ID。
3) 我们往 Qdrant 里存什么
Qdrant 不是一个大杂烩。我们把记忆拆成几类 collections,每一类有明确的 payload 结构和召回目的:
| Collection | 内容 | 用途 | | --- | --- | --- | | trade_cases | 历史交易片段:入场/出场、结果摘要 | 相似交易案例召回 | | risk_events | 哨兵告警、黑天鹅、极端行情、风控阻断 | 极端风险类比 | | strategy_reviews | 策略复盘、失败原因、改造建议 | 研发防重复踩坑 | | experiment_results | 回测或 dry-run 实验摘要 | 实验结论召回 | | failure_patterns | 已知失败模式:过拟合阈值、regime luck、proxy 不匹配 | 失败模式预警 | | agent_lessons | Codex/Hermes/OpenClaw 协作经验教训 | 工作流复用 | | docs_knowledge | 系统架构文档、部署说明、流程规范 | Agent RAG 与文档检索 |
每一类记忆都有 payload 过滤字段:候选 ID、市场、timeframe、策略族、风险级别、时间窗口。这意味着你可以问"有没有 risk_004 类型的 short guard 失败案例",而不是漫无目的地搜。
入库时只收高信噪比样本。不是所有交易都值得记住——只有那些能提供教训的才值得被嵌入。
4) 我们绝不往 Qdrant 里存什么
记忆层不是保险柜,更不是执行器。以下内容不会进入 Qdrant:
- 交易所凭证、API key、secret
- 原始账户导出、实时余额
- 唯一订单事实(那是 SQLite/DuckDB 的事)
- 可执行交易指令
- dry-run 或 live trading 的"批准标志"
- 服务器运行时细节、内网路径
一句话:Qdrant 只记教训,不记凭证,不记事实,不记命令。
5) 向量检索会说"像",但不会说"安全"
这是和第 6 篇 How We Judge a Strategy Candidate Before Dry Run 直接呼应的一篇。
在第 6 篇里,我们说 Qdrant 召回不能驱动发布决策。在这里,我们把这个规则反过来看:Qdrant 召回的真正价值,不是告诉你"这个候选可以上",而是告诉你"这个候选和过去某个被阻断的案例很像——你应该去读那份报告"。
向量检索能告诉你"这看起来熟悉"。它不能告诉你"这个可以交易"。
一个被 Qdrant 召回的案例只能触发复核,不能触发放行。候选晋级仍然需要回到事实账本的七项门禁:代码编译、交易次数、直接归因、OOS 验证、近期覆盖、权限隔离、事实裁判。
这在我们的真实流程中是这样运作的:
1. OpenClaw 哨兵产生告警 → Qdrant 召回相似风险事件。 2. Codex 开发新候选 → Qdrant 召回类似失败模式。 3. Hermes 做离线研究 → Qdrant 召回长期记忆中的相关历史。 4. 召回结果作为"应该读什么"的线索,不作为"应该做什么"的决策。
6) 最小可行记忆层
如果你也在搭建交易系统的记忆层,以下是最小可落地的七步:
1. 导出干净的研究事实——不是原始日志,是结构化复盘和实验摘要。 2. 生成短且带 source ID 的案例摘要——每条记忆必须有来源可追溯。 3. 只嵌入高信噪比案例——低质量样本进库会污染未来所有召回。 4. 存 payload 过滤字段——候选 ID、市场、timeframe、风险级别,不然召回就是瞎碰。 5. 做新候选工作前先跑召回——先看看历史上有没有类似的坑。 6. 每次召回都要交叉验证源报告——不只看 Qdrant score,要回链原始文档。 7. 让门禁而不是记忆决定晋级——召回能提醒你风险,但不能替你放行。
做到这七步,你的系统不一定更赚钱,但它会多一个能力:不会在同一个坑里摔两次。
7) 运营规则
最后,用一句话总结整个记忆层的定位:
> 事实裁决。记忆提醒。研究提案。门禁裁决。执行层执行。
Facts decide. Memory reminds. Research proposes. Gates approve or block. Freqtrade executes.
这不是一个 AI 记忆教程。这是一个工程系统的记忆纪律——记住该记住的,忘掉不该记住的,永远不让记忆越权做决定。
再次强调:这篇文章是 research only,not financial advice;backtests are not live performance;not an instruction to trade。语义召回不是交易证明,Qdrant 召回不构成 dry-run 或 live 授权。