How We Judge a Strategy Candidate Before Dry Run

在 ProBitForge,回测好看只是候选诞生的起点,不是它晋级的终点。
一个策略候选能不能从"研究层"走到"dry-run",需要过一套硬门禁——每一项都来自我们在真实风险候选上踩过的坑。
这篇文章是 research only,not financial advice;backtests are not live performance;not an instruction to trade。
如果你刚来 ProBitForge,可以先看我们的系统定位:<https://www.probitforge.com/what-probitforge-is-building/>
1) 问题的本质:回测好看 ≠ 可以上线
回测是研究工具,不是上线许可。
在之前的 Why Backtests Lie 里,我们说过:回测曲线可以隐藏过拟合、费用缺失、样本偏差和 regime luck。在这里,我们把同一个问题推到更具体的层面:
一个候选在什么条件下,才有资格从"研究素材"变成"可试运行的策略"?
这不是一个学术问题。在我们的风险候选评审里,有好几个候选的历史回测和 walk-forward 都是正向的,但近期成交级对齐直接把发布阻断——历史数据支持继续研究,但近期数据不支持上线。
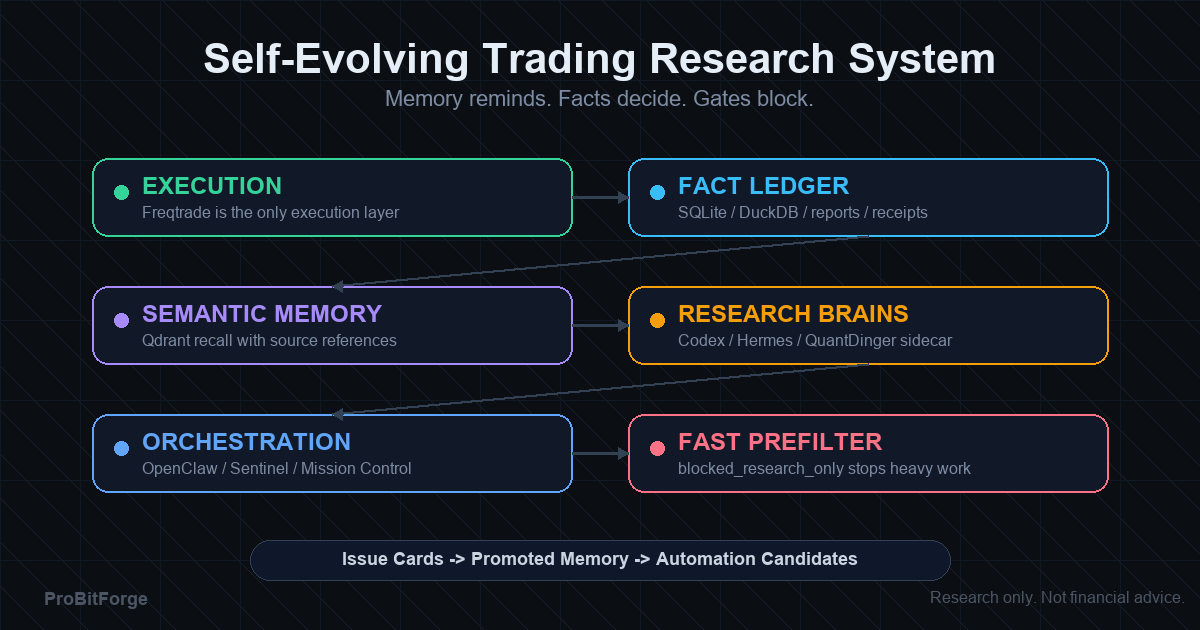
2) 我们用到的七项硬门禁
以下是我们对每个风险候选做发布评审时实际使用的门禁框架。它不是理论模型,而是从 risk_002 到 risk_019 十多个候选的评审过程中提炼出来的。
门禁 1:策略加载与基础编译
听起来很 trivial,但这是第一步:策略代码能不能被 Freqtrade 正常加载?新增脚本能不能通过 py_compile?
如果代码都跑不起来,后面的门禁全是空的。
现实案例:risk_004 的两个 ShortMpgConfirmedGuard 策略加载和编译全部 PASS,工程入口可用。但如果加载就 FAIL,候选直接退回工程层修复,不做任何归因分析。
门禁 2:交易次数(Trade Count)
交易次数是最容易被忽视的硬约束。
一个候选只在 6 笔匹配交易上表现正向,你真的敢让它上线吗?
现实案例:risk_006 的 release review 里,直接归因 net 是 +37.32,但匹配交易只有 6 笔——低于发布最低要求 20 笔。哪怕数值好看,交易次数不够,置信度就不够。我们写得很明确:unique_trade_count_below_release_min: 6 < 20。
这背后的逻辑很简单:6 笔交易的"正向结果"太容易被 regime luck 解释了。你至少需要 20 笔以上的样本,才能初步排除"恰好赶上了一段好行情"。
门禁 3:直接归因 vs Proxy 归因
我们把归因拆成两种:
- 直接归因(direct attribution):候选的拦截/放行决策能匹配到真实成交记录,归因有事实支撑。
- Proxy 归因:没有匹配成交的决策,只能用假设的 24h forward return 做代理评估。
Proxy 归因不是无效证据,但它不能替代成交事实。
现实案例:risk_006 的 BNB guard,直接归因 net +24.58,但 proxy 归因 net -9.72——直接正向、proxy 负向,这是一个典型的 release risk。再比如 risk_004,24h proxy 净保护只有 +28.44,但有 no_trade_match=29,意味着近一半决策只能用 proxy 证据,不能当作成交事实。
门禁规则:直接归因必须正向;如果 proxy 归因负向,至少需要标注为 PASS-WATCH 或 FAIL-WATCH,不能忽略。
门禁 4:样本外验证(OOS / Walk-forward)
历史 walk-forward 通过是好事,但它只是研究级证据,不是上线级证据。
现实案例:risk_004 的 extended walk-forward PASS,total_profit_abs_delta=930.34,数值很好看。但同一候选在近期 30/60/90 天成交级对齐全是负向:
- 30d direct net:
-277.52 - 60d direct net:
-456.02 - 90d direct net:
-402.80
历史 OOS 通过,近期 OOS 全负——这说明候选可能只在特定历史窗口有效,不是一个跨 regime 稳定的过滤器。
门禁规则:近期窗口 OOS 必须至少有一个档正向,否则直接阻断。
门禁 5:近期覆盖(Recent Trade Alignment)
这是我们从 risk_004 评审中学到的最重要的一条:历史证据不删除,但发布判断必须以近期覆盖为准。
risk_004 的历史评审文档前半部分全是正向结论,后半部分被近期数据覆盖成"release_blocked_recent_trade_alignment"。我们不改写历史——历史有价值,但它不代表候选当前能上线。
门禁规则:发布判断必须用最近 30/60/90 天的成交级对齐做覆盖裁决。历史正向不删除,但近期负向必须触发阻断。
门禁 6:权限隔离(Safety Column)
在我们的事实账本里,每个候选都有两列硬门禁:dry_run_allowed 和 live_trading_allowed。
默认值都是 false。
只有当所有其他门禁通过、用户给出明确文字授权(必须包含"允许 xxx 进入 dry-run")、发布回滚计划存在、近窗验证正向——才能把 dry_run_allowed 改成 true。
live 永远晚于 dry-run;dry-run 未通过前,live 直接判定 FAIL-BLOCKED。
现实案例:risk_019(新信号族侦察)的闸门合同里写得很清楚:must_keep_dry_run_live_false_until_gate: True。连闸门合同都把这条写成了硬约束。
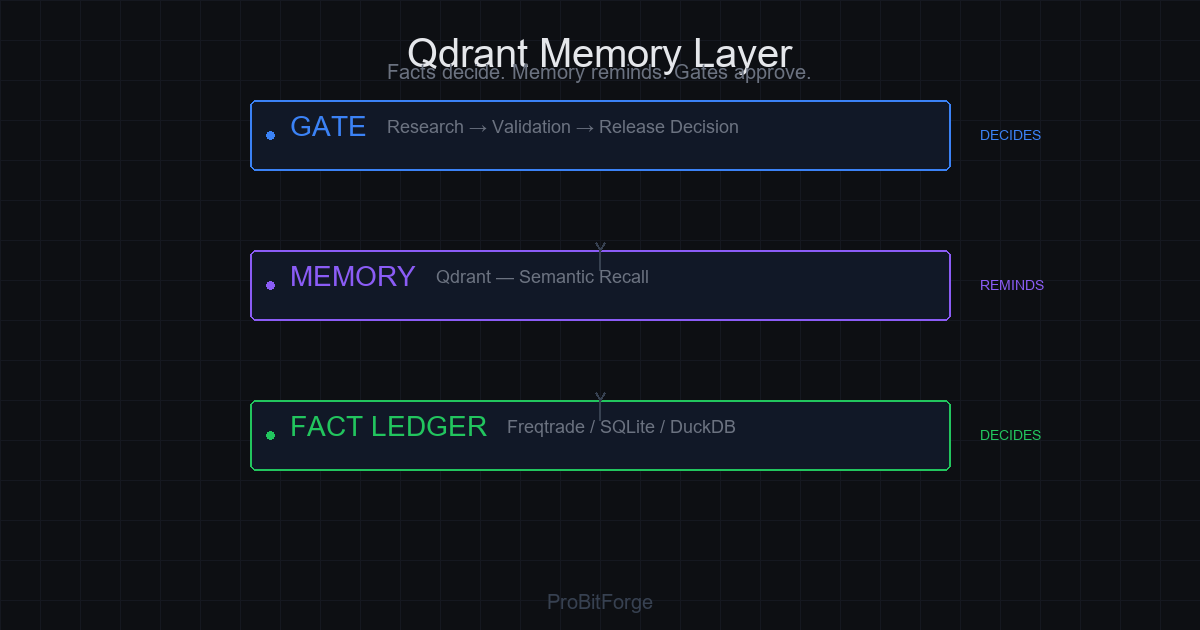
门禁 7:Qdrant / 语义记忆的边界
Qdrant 可以帮你召回"类似行情下我们曾经怎么死过",但它不能做裁判。
现实案例:risk_004 的 Qdrant 宽泛检索 Top1 有时召回旧 risk_002,而不是 risk_004。这说明语义记忆需要 candidate_id filter 和 rerank,不能让语义召回直接驱动发布决策。
我们的规则:
- Qdrant 只做召回辅助,不做事实裁判。
- 事实裁判是 SQLite/DuckDB 和 JSON artifact。
- 语义召回结果必须和事实账本交叉验证,不能单独作为晋级证据。
3) 一张门禁评分卡
综合以上七项,我们给每个候选打一张评分卡:
| 门禁 | 要回答的问题 | 不通过时 | | --- | --- | --- | | 策略加载与编译 | 代码能跑吗? | 退回工程层 | | 交易次数 | 样本够吗? | 阻断发布,继续收集数据 | | 直接归因 vs Proxy | 真成交支持还是假假设支撑? | proxy 负向标注为 WATCH | | OOS / Walk-forward | 跨窗口还成立吗? | 阻断发布 | | 近期覆盖 | 最近 30/60/90d 还正向吗? | 阻断发布,历史不删 | | 权限隔离 | dry_run_allowed/live_allowed 都是 false 吗? | 必须是 false 直到显式授权 | | Qdrant 边界 | 语义召回有没有干扰发布判断? | 补 filter/rerank,不改裁判权 |
所有门禁全部 PASS 才能考虑晋级。一项 FAIL 就阻断——不是"差不多能用",而是"证据不够,停"。
4) 两个真实阻断案例
案例 A:risk_006——交易次数不够
risk_006 是 risk_005 的改进版,BNB guard 和 ETH high-ATR guard 的直接归因都是正向。但:
- 匹配交易只有 6 笔,低于发布最低 20 笔。
- proxy 归因负向
-9.03。 - ETH ATR threshold sweep 显示 0.008 和 0.010 产生相同结果,说明阈值不是"独特发现",只是恰好在这个小样本上看起来不错。
发布决策:release_blocked_research_pass。比 risk_005 更好,但不够上线。
案例 B:risk_004——近期覆盖翻转
risk_004 的历史评审全是正向:walk-forward PASS、shadow 事件 PASS、直接 blocked-trade 归因从负值拉到 +758.42。
但近期 30/60/90 天成交级对齐全负。历史正向不删除——它说明候选曾经有效,或者至少在特定窗口有效。但发布判断必须以近期为准:近期全负 = 阻断。
这个案例教会我们一件事:一个候选可以同时是"有价值的研究素材"和"不能上线的策略"。这两种判断不矛盾。
5) 为什么"允许停止"比"允许微调"更重要
在很多候选评审中,我们看到一个典型模式:阈值族微调。
你不断调整阈值,回测曲线确实好看一点,但稳定性没有变硬——你只是在把噪声当信号。
risk_006 的 ETH ATR threshold sweep 就是这个模式的缩影:0.008 和 0.010 在当前小样本上表现相同,0.012 直接翻转负向。这不是"发现了最优阈值",而是"小样本上的阈值只是碰巧"。
所以我们的态度是:
1. 证据不到阈值,不晋级——不是"差不多能用",而是"可复现、可解释、可样本外站住"。 2. 允许停止,不允许自欺——停止某条路线,反而是在节省未来的风险预算。 3. 阻断也是有价值的产出——一个被阻断的候选,如果留下了清晰的失败原因,比一个靠运气通过的候选更有研究价值。
6) 给想复刻这套门禁的人
如果你也在做 AI 加密量化,想在策略候选上线前加一层硬门禁,以下是最小可落地的检查清单:
1. 代码能跑、能编译——别在基础设施上浪费时间。 2. 交易次数 ≥ 20——别在 6 笔交易上做发布决策。 3. 直接归因正向——proxy 归因不能替代成交事实。 4. OOS 至少一个窗口正向——全窗口正向更好,但至少不能全负。 5. 近期 30/60/90 天覆盖正向——历史正向不删,但近期负向必须阻断。 6. 权限隔离:dry_run 和 live 默认 false,只有显式授权才能改。 7. 语义召回不做裁判——只做辅助,事实账本做裁决。
做到这七条,你的系统不一定赚钱,但它会具备一个更关键的能力:不会把回测幻觉当成上线许可。
7) 再次强调
这篇文章是 research only,not financial advice;backtests are not live performance;not an instruction to trade。
门禁框架本身也不是万能的——它只是我们当前能做的最务实的事:把"感觉不错就上"变成"证据到了才放",把"回测好看"变成"可验证、可审计、可阻断"。