Building a Self-Evolving Trading Research System
复杂交易研究系统最容易忘记的,不是某次回测的数字,而是为什么当时停下来了。
一个候选被阻断,三个月后没人记得具体原因;一份旧文档还在目录里,和新版门禁结论互相矛盾;向量库召回了"相似案例",但没人核对它能不能当作证据。于是系统看起来在运转,实际上在重复同一种错误。
ProBitForge 把"自我进化"定义得很保守:进化的是流程、记忆、路由和门禁,不是绕过门禁去交易的能力。
这篇文章是 research only,not financial advice;backtests are not live performance;not an instruction to trade。自我进化改善的是证据质量与阻断时机,不保证交易表现。任何 LLM、向量库、外部研究平台或仪表盘,都不得绕过执行门禁。
如果你希望从系统边界开始阅读,可以先看:我们如何评审策略候选能否进入 dry-run。记忆层细节见:用 Qdrant 搭建交易研究记忆层。
1) 自我进化不是自主交易
在交易研究里,"更聪明"不应等于"更急着下单"。
安全的自我进化系统,学的是三件事:
1. 记住失败:阻断原因、覆盖缺口、权限越界尝试,不应随一次跑批结束而消失。 2. 路由权威:谁可以提议、谁可以证明、谁可以执行,必须写死在架构里。 3. 更早阻断:在重型回测、样本外、向量入库之前,先用轻量预筛拦住明显不合格的路径。
> 安全的自我进化,不是学会绕过门禁,而是学会解释门禁为什么存在。
2) 权限分层:谁负责什么
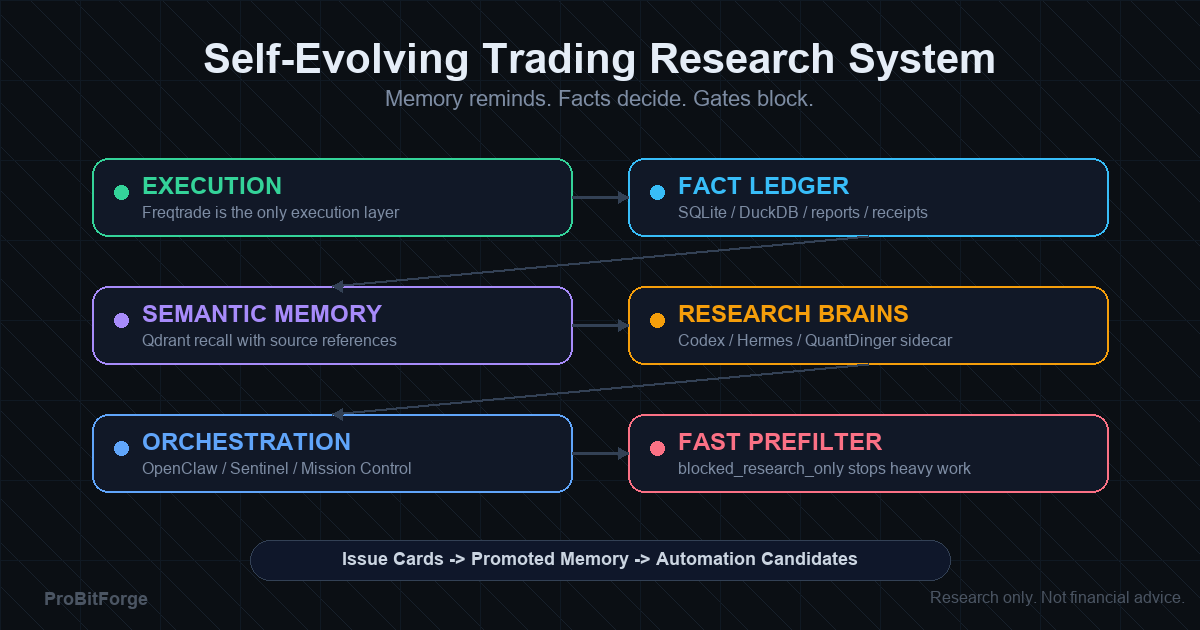
我们把系统拆成五层,每层有硬边界:
| 层级 | 组件 | 职责 | 硬边界 | | --- | --- | --- | --- | | 执行层 | Freqtrade | 回测、dry-run、实盘执行 | 唯一可控的执行路径 | | 事实账本 | SQLite / DuckDB / JSON 报告 / Markdown 回执 | 可审计事实与门禁记录 | 精确事实优先于记忆摘要 | | 语义记忆 | Qdrant | 相似案例召回、带来源引用 | 相似不等于证明 | | 研究脑 | Codex / Hermes / QuantDinger | 假设、诊断、工程变更、外部研究 | 不得直接授权 dry-run/live | | 指挥与可见性 | OpenClaw / Sentinel / Mission Control | 监控、编排、报告、运营记忆 | 不得隐藏执行通道 |
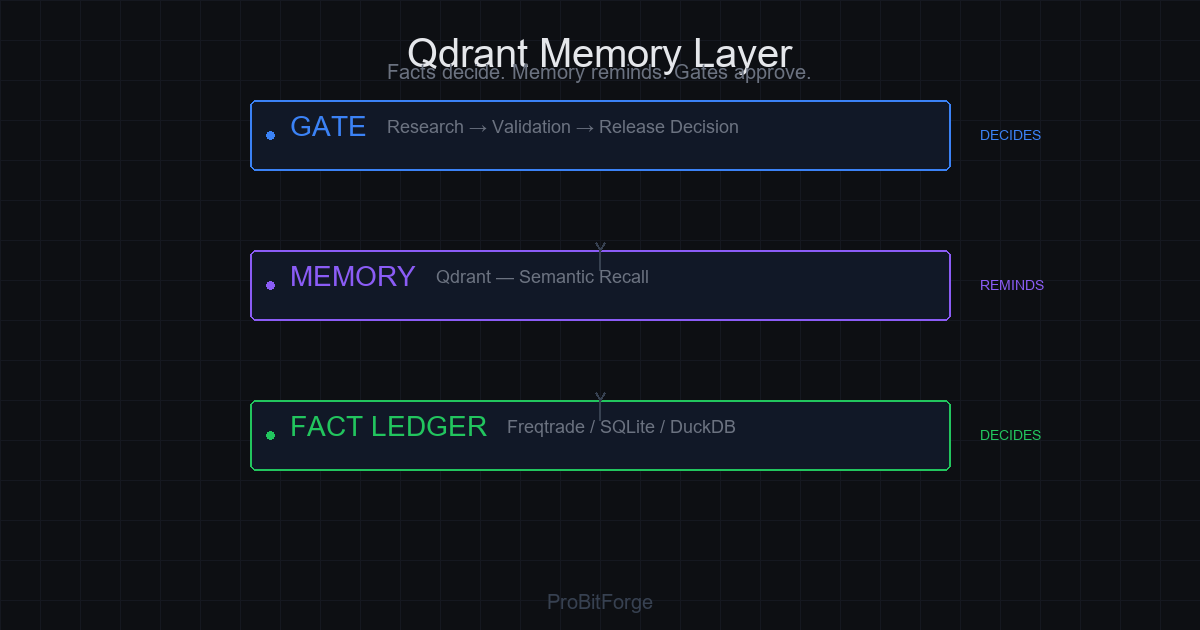
一句话:Memory reminds. Facts decide. Gates block.
Freqtrade 执行;账本记事实;Qdrant 提醒相似;研究脑提方案;指挥层管可见性与编排;门禁在晋级前裁决。
3) 文档治理:别让旧笔记覆盖新门禁
工程系统里,文档也会"腐烂":旧回执、冻结方案、已废弃策略说明,和新版门禁结论并存时,人和 Agent 都会读错顺序。
我们把文档分成五类状态:
canonical:当前权威口径active:正在使用、可被引用receipt:某次验证或发布的回执frozen:历史快照,只读参考deprecated:已废弃,不得覆盖现行门禁
这给未来的 Agent 和工程师一个阅读顺序:先 canonical/active,再 receipt,frozen/deprecated 仅作历史对照。否则一条三年前的"可以上 dry-run"笔记,可能误伤今天的 blocked_research_only 状态。
4) Issue Memory Card:把生产问题变成机构记忆
单次失败跑批的价值很低。高价值的是:把失败结构化,让它下次还能被召回。
Issue Memory Card 是我们用的最小学习单元,典型字段包括:
- 症状(symptom)
- 影响(impact)
- 根因(root cause)
- 修复(fix)
- 验证(verification)
- 预防(prevention)
- 来源引用(source references)
- 置信度(confidence)
- 记忆晋升状态(memory promotion status)
生命周期:
``text raw_event -> hypothesis -> verified_issue -> lesson_candidate -> promoted_memory -> deprecated_memory ``
安全示例:某策略候选因 K 线覆盖不完整被阻断。错误做法是让这次失败消失在日志里;正确做法是写成卡片——"coverage gap blocks promotion"——下次预筛时召回,提醒研究员先补数据,而不是直接开重型回测链。
当前体系里,问题记忆与 Qdrant 摘要严格分离:召回可以提醒,但不能替代事实证明(eligible_as_proof=false)。
5) Qdrant:提醒层,不是裁判层
Qdrant 回答的是"这像什么",不是"这是不是真的"或"能不能交易"。
我们往 Qdrant 里放的是脱敏摘要 + 来源引用,不放:
- 唯一事实本身(PnL、订单、精确回测数字)
- dry-run/live 授权
- 把相似案例当作统计显著性
每条召回必须能回链到事实工件:报告 ID、账本记录、Issue Card 路径。否则语义记忆会从"提醒"滑向"幻觉式证据"。
更完整的记忆层设计,见前文 Qdrant 记忆层文章。
6) Fast Prefilter:重型研究链的"前门保安"
在启动昂贵的 Hermes/Freqtrade 链路之前,我们先跑一层快速预筛(fast prefilter)。
它检查的典型项包括:
- 当前门禁状态(是否仍
blocked_research_only) - K 线覆盖是否完整
- 上游事实链是否过期或阻断
- 问题记忆卡是否命中当前候选
- Qdrant 召回边界(是否被误当作 proof)
- QuantDinger 边界(是否保持
external_research_only)
当预筛返回 blocked_research_only 时,下游重型动作会被跳过,例如:
- K 线刷新
- 晋级型回测 / 样本外
- Qdrant ingest
- dry-run / live 相关配置写入
这不是"偷懒",而是权限保护 + 算力保护:在证据不足时,不让系统假装自己在做严肃研究。
以 2026-05-19 的验证状态为例(概括性描述,非实时承诺):
- 决策:
blocked_research_only - 硬阻断项:4 项
- dry-run / live:保持关闭
- 重型研究链:未继续执行
典型阻断原因包括:Hermes 日终复核已给出 research-only、K 线覆盖仍有缺口、上游事实链过期或阻断、当前候选命中 P1 级历史问题记忆。QuantDinger 仍保持外部研究侧车,不具备执行或晋级权限。
7) 自我进化闭环(端到端)
把上述组件串起来,闭环是这样的:
``text 问题或阻断出现 -> 写入事实工件 -> 创建 Issue Memory Card -> 召回相似案例(Qdrant,带来源) -> 修复或维持阻断 -> 验证 -> 晋升或拒绝记忆 -> 生成自动化候选 -> 更新门禁或预筛规则 ``
注意顺序:先事实,再卡片,再召回,再验证,最后才谈晋级。 跳过任何一步,"进化"都会退化成过拟合或权限漂移。
与执行层的关系可以概括为:
``text Execution layer -> fact ledger -> semantic memory -> research brains -> orchestration layer -> fast prefilter -> issue memory evolution ``
8) 给搭建者的检查清单
如果你要复刻一套"能进化但不失控"的研究系统,至少做到:
1. 执行与研究分离:只有一个组件能触达 dry-run/live。 2. 事实账本先行:SQLite/DuckDB/报告/回执,可回链、可审计。 3. 向量召回当指针:相似案例提醒你去读事实,不能代替事实。 4. 每个组件有权限等级:写进矩阵,不让 Agent "顺手"越权。 5. 重复阻断写成 Issue Card:别让同类失败只活一次。 6. 重型链路前跑预筛:blocked 就停,别假装继续研究。 7. 阻断状态要 sticky:证据清空前,不要自动"差不多能上了"。 8. 公开发布回执,不发表承诺:读者看到的是验证过程,不是收益保证。
做到这八条,系统未必更赚钱,但会更难重复同一种工程错误——这本身就是自我进化的最低合格线。
9) 最后再强调一次边界
AI 和自动化可以读文档、写回执、提假设、跑诊断、生成工程变更。
它们不应该在没有验证、没有门禁、没有审计的情况下,直接触达资金。
这篇文章是 research only,not financial advice;backtests are not live performance;not an instruction to trade。自我进化改善的是流程与证据路由,不保证交易结果。